

What I Learned Building FIRE - A Neural Network Approach to Pitch Modelling
I Descended into the Gradients... And Survived to Tell the Tale

There is a mostly-correct axiom that over-thinking a problem, sometimes referred to as analysis paralysis, can be counter-productive. Indeed, for me this caused a serious case of researcher’s block. I’ve been ruminating for quite some time on how to build a novel pitch modelling framework. Research for me is mostly about exploring new ground, and teaching myself something new, with the outside chance that whatever I’m working on will produce something useful. This blocked me from doing any productive research for quite some time.
Today’s story will perhaps convince you that over-thinking a problem can sometimes be good. After months of contemplation, I arrived at a framework I believed in: I would feed a neural network all the context, including an entire pitcher’s arsenal, the strike zone, count, base/out state and the handedness matrix. I had oscillated between selecting just the Primary, Secondary and Tertiary pitches, or describing the entire arsenal, and eventually I decided to split an arsenal into 8 pitch types and then feed the model 8 variables (pared down to 6 in the current version).
But let us back up a little bit, as I want to share my research story, partly since I’m really proud of what I’ve been able to do, but more importantly, to hopefully inspire a fellow researcher out there who thinks something ambitious is not possible. I’m not a particularly talented programmer, nor am I an expert in anything I attempt to do. I’m also over 40 and mostly just dabbling. Despite that, I was able to build a neural network pitch model, from scratch, including the entire neural network library. If I can do it, you definitely can do it.
It All Started with Learning Rust
I have an aversion to using out-of-the-box machine learning toolkits. It’s probably one of my biggest weaknesses as a researcher. This should in no way, shape or form be interpreted that I see anything wrong with using highly successful machine learning frameworks such as XGBoost. I just find it exponentially more interesting to build my own framework and/or algorithm from scratch.
To be able to do research like this, I needed to learn a systems programming language. So I taught myself Rust, which makes doing performant parallel programming really easy, with performance on par (or exceeding) C/C++. If you’re like me and want to build out your own algorithms, I highly recommend Rust. I’d be delighted to help you along the way. Otherwise, stick to Python and you’ll likely be much more productive.
A Descent into The Gradients
There’s a fantastic neural network library in Rust called BURN. If you’re looking to build a production-class neural network, I highly recommend it. My initial foray into neural networks began using this library. I failed. Hard. I didn’t understand anything I was doing, and was just turning knobs at random. Concepts like batch size, learning rate, gradient descent, were all abstract notions that I kinda-sorta understood, but in truth, really didn’t.
I didn’t want to give up. I really wanted to explore neural networks for baseball research. So I decided to build a neural network library, from scratch, in Rust.
First Version of My Neural Network Library
It’s almost comical looking back on it. My initial library didn’t have any knowledge of gradients, since I really couldn’t wrap my head around what the heck a gradient was, and how neural networks used them to optimize their parameters. My first library used a brute-force approach. It would randomly tweak a parameter, then check to see if that improved the network. If it did, keep the change, otherwise, reject it.
This worked, but hit hard computational limits, as the computational cost grew exponentially with the size of the network. The moral of this story is that just getting a working prototype, even a laughably terrible one, is critical for building a platform for doing something better. Just build something; it will make the second version much easier.
Version 2 - Learning About Gradients
I spent months trying to understand what the heck gradients were. ChatGPT would tell me, you calculate the gradient and then move in the opposite direction of the gradient. So I’d ask, “how do I calculate the gradient”. The answer was “do a forward pass and then back-propagate”. Great. I still had no idea how to even begin doing that.
So I fumbled about, read lots of things, until at long last I arrived at a YouTube video that finally explained all of this to me, since it built everything from the ground up:
This video changed my life. If it weren’t for this video, I may have given up on learning gradient descent. There’s almost no chance you’re reading this Andrej, but you have my most heartfelt thanks for creating this video.
Once I watched this video a few times, I finally understood what I was missing. A neural network is really just a series of simple math operations (activation functions sometimes excluded). Each operation produces a local derivative. Then it’s just a matter of applying the chain rule and presto, you can calculate the gradient at every single step, starting with the loss at the very end, all the way backwards through the network. The forward pass was simply about getting all the local derivatives. It took some trial and error (lots of error), but after graphing things out, I finally got it to work.
Xavier Initialization + Normalization
Along the way, I discovered I needed to apply Xavier initialization. Don’t remember why or how that came up, but it’s important for keeping gradients stable. It’s also important to normalize all your input features, which helps maintain a stable training loop. There are many strategies here, many of which I have yet to implement (such as dropout regularization).
THE MODEL
If you’ve made it to here, excellent. Let me describe what I’ve built, what it’s good at and what it gets embarassingly wrong.
All The Context
The model uses the following binary features to make predictions:
balls_0, balls_1, balls_2, balls_3
strikes_0, strikes_1, strikes_2
is_lhb, is_rhb, is_lhp, is_rhp
I theorized that splitting up each ball/strike state was superior in a neural network so that it wouldn’t treat balls and strikes as continuos variables. I have no evidence to support this theory as a superior approach.
I then included various pitch characteristics:
Spin Axis X/Z (unitized spin axis so the network doesn’t need to understand what 162° means)
Spin Rate
Pitch Velo, IVB/Flight, HB/Flight
Release (X/Z/Extension)
Plate X/Z, Strike Zone Top/Bottom
Pitcher Height
Inferred Movement deviation from the spin axis
Pitch Usage (vs lhb/rhb)
Finally, I added in the arsenal context 8 pitch types X 6 features each
FF, SI, FC, SL, CH, CU, ST, FS
HB/Flight, IVB/Flight, Usage (vs lhb/rhb), Velo, Plate X/Z (vs lhb/rhb)
This works quite well, but I think caused a problem for pitchers who are primary FC guys without a FF or SI (Clase and Burnes). More on this later.
Step 1 - Classification
The first step was to use a classification network to predict the probability that the pitch would fall into one of these 5 categories:
Ball (a pitch that is not swung at and called a ball)
Foul
Strike - Called
Strike - Swinging
In Play
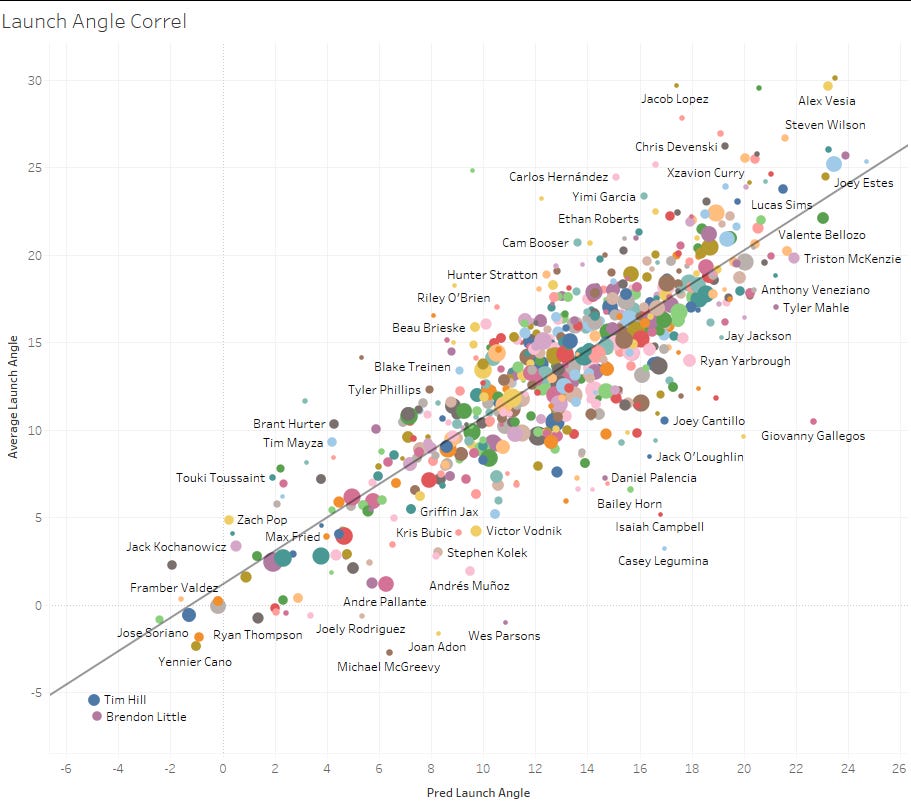
Step 2 - Exit Velo and Launch Angle Distributions
Rather than output a predicted exit velo and launch angle for each pitch, we predict a distribution, using classification to fit to large-ish buckets. This worked surprisingly well. Here’s what that looks like for Clay Holmes’ sinker compared to how the model predicts a league-average sinker:

We see a natural left-skew for Holmes, indicating he is limiting launch angles with his sinker shapes and locations.

For sinkers, we get a 0.54 R² correlation with a minimum of 25 pitches. If we zoom out to all pitches, this increases to 0.66:
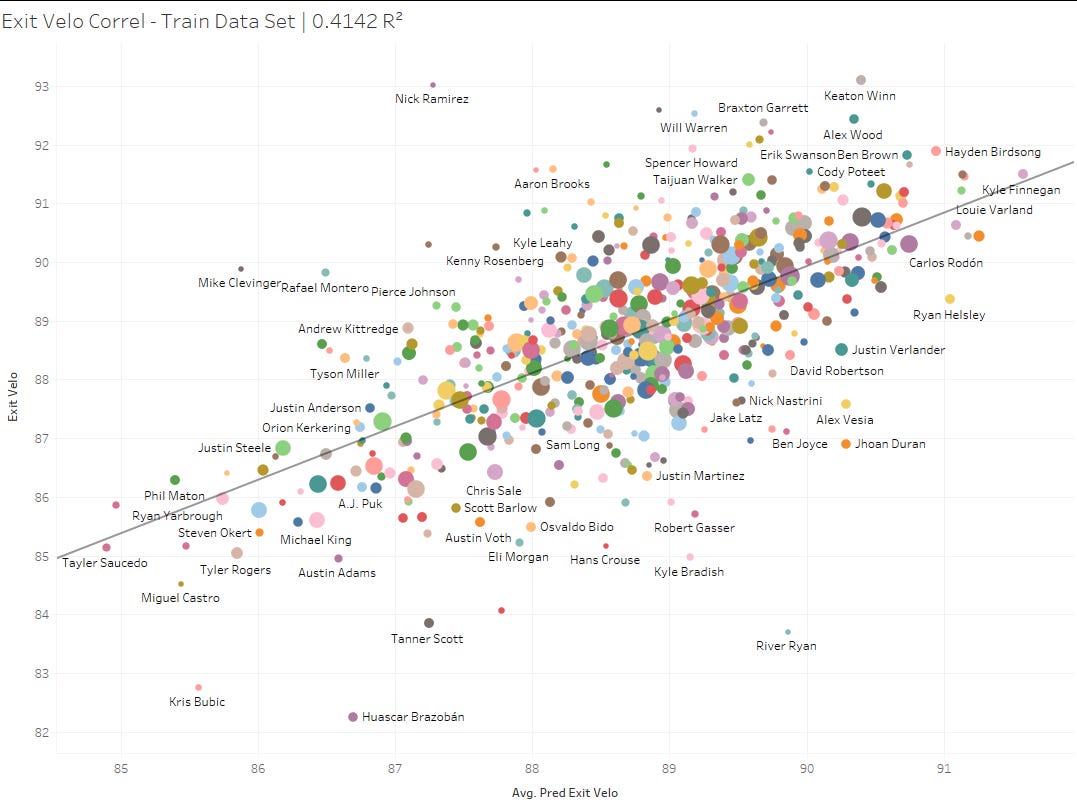
For exit velocity, we get a surprisingly strong correlation as well. Here we’ll look at the validation data set, which the model has never seen:

Strangely it outperforms the training data set, which may have had some more inherent noise:
The Distribution Is Key
Since we have a distribution, we can assign a probability to every EV + LA combination, and then add up the weighted average of the in play events. I can’t stress how important this is for modelling in play events. EVs and LAs have weird interactions, which means that just taking the mean EV and mean LA is going to give you a potentially imprecise view. We must consider the full distributions of both.
I considered investing in creating a mixture density network to model skew-normal distributions, but I’m not convinced it’s worth the complexity cost. Here’s how this worked out when predicting home runs:

In my early runs when I was attempting to directly predict Home Runs in “Step 1”, I would max out at tiny correlations that were basically all noise. I don’t think this is particularly amazing, but HRs are rather stochastic, so I’m not sure what a “good’ correlation is here.
Validating The Model

I may have over-fit the data somewhat with respect to called strike predictions. The validation data set pitcher-level correlation is decent, but quite a bit worse than the training set.

The model severely underrates Strider and Bautista from a swinging strike perspective, which is worrisome, however, overall the pitcher-level performance is close to the training data set.

I’m pretty happy with this part of the model, no big outliers here.
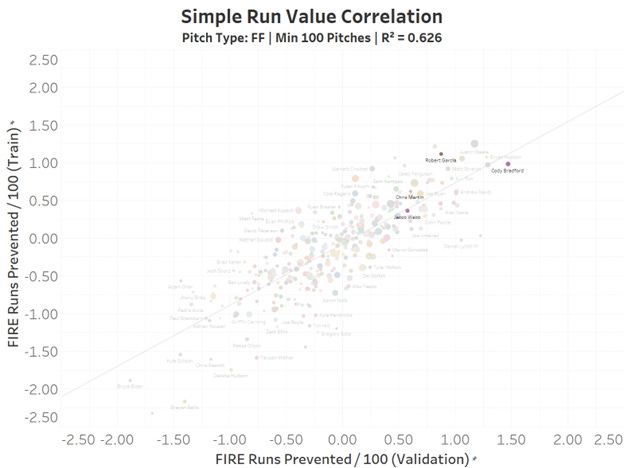
Converting to Simple Run Values
Each EV/LA combo had a RV associated with it, so that part was easy. For the other 4 outcomes, I decided to do something simple, yet “wrong”. I took the average run expectancy delta for each of the possible outcomes (ball, strike, swinging strike, foul) and assumed that would average out the leverages. I’m both pretty sure this is “wrong”, but I’m also pretty sure it’s “mostly correct”. I was exhausted from spending months building this, so this will need to suffice for now. I’m calling these “Simple Run Values”.
Who Does FIRE Love? Who Does FIRE Hate?
Let’s do ye old eye test to see how well it captures performance. The “Train” data set is 2024, and the “Validation” data set is 2023.

FIRE loves Justin Steele. It thinks he’s a god. Also, I think the Rangers might be using something similar to FIRE:
FIRE really likes what Bradford and Garcia did with their FF, and to a lesser extent Jacob Webb and Chris Martin. It also really likes Bailey Falter, which is a tad worrisome, and not something I agree with. Fortunately, this is offset by its supreme confidence in Tarik Skubal’s pitching.

I’m glad Hader tops this list. Yes, I checked out who Brennan Bernardino is and, yes, his sinker actually performed well in 2024.

Hunter Brown’s sinker pops if we up the sample size.

Remember that these include locations. Might indicate that Taylor Rogers was unlucky last year, or that FIRE is just plain wrong. A.J. Puk is a monster.

I really like this list. Guess who signed Luke Jackson? The Rangers. Did I mention FIRE loves Justin Steele? It might be his biggest fan.
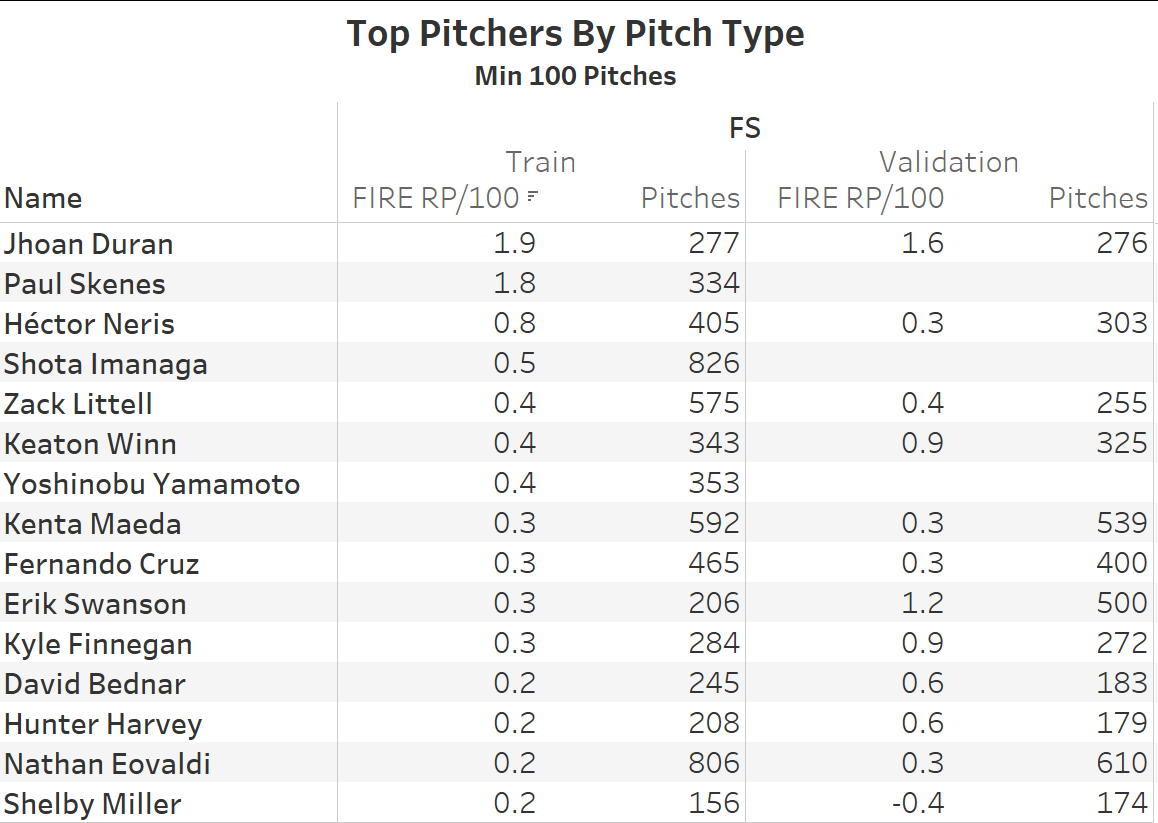
This is my favourite list. Other models struggle to properly capture the Splinker. FIRE just shrugs and says “basically unhittable”. Ben Joyce’s splinker would be first by a mile if we made it only a 6 pitch minimum.

Cristian Javier stands out for his improvement, which are substantiated by his FG run values. Eli tops the list!!! Always gonna be happy with that. Oh, and there’s Garcia and Webb. Not a bad list, IMO.

If we sort by 2023, Devin Williams is close to the top, though it wasn’t impressed with his 165 pitch 2024 sample.

Kikuchi is interesting. I don’t know if I agree or disagree, but FIRE is consistent year over year.

I mentioned above that the model reads a lot into fastball characteristics, so when a pitcher doesn’t have a FF, it can get confused. This means FIRE is substantially underrating Clase and Corbin Burnes. I’ll definitely be fixing that going forward.
What FIRE Gets Very Wrong
FIRE thinks Skenes is an average pitcher, which is basically disqualifying on its own. It thinks Bailey Falter is a GOD, also potentially disqualifying on its own. It underrates pitchers who throw a cutter first, and don’t throw a fastball or sinker. It also thinks Felix Bautista’s 2023 was bad. That’s only several data points, but for me, that’s enough to tell me it’s too noisy to be reliable. If it gets Bautista’s fastball wrong, it’s broken.
Concluding Thoughts
FIRE is not production ready. It’s an interesting first start, and gives me something to build off as I work towards a production quality model. I’ve learned a ton, and hope to have something that I can use on a day-to-day basis by the end of the season. I strongly believe that neural networks are the way to go to properly model arsenal interactions, and I’m hopeful that I’ll be able to improve on the prototype version.
Fantastic, really looking forward to updates whenever they come.
building your own neural net implementation in rust is really interesting. would love to look it over. have you made the repo available publicly by any chance?